Facet Labs experience
Published: 10-03-2023
Some thoughts and extra info from designing and building diamond sorting machines - software focused.
I started doing some freelance work in 2021 which turned in Facet Labs Ltd. - a collaboration to provide R&D services in the diamond industry, including designing prototype sorting machines.
As well as carrying out mechanical/electronics design work and doing a lot of the manufacturing, plenty of time was spent developing a web-based machine control system. This was a good chance to bring in all the technologies I was integrating at my old job without the pre-existing technical debt.
Having all the shiny new toys available isn’t an excuse for over engineering a product though, especially in the prototype stage. The machine designs followed a fairly natural evolution:
- Simple first machine with analogue controls
- Analogue controls replaced by SBC
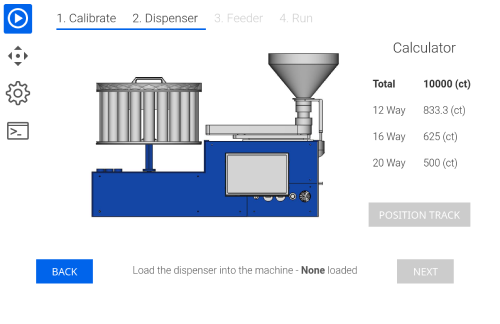
- Touch screen and user interface added
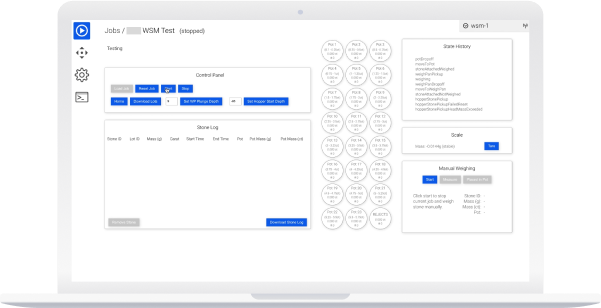
- Controls exposed over the machine API
A separate more complicated machine was required for a different process and this triggered the following evolutions:
- Subsystems with standardised interfaces introduced
- SBC used as headless controller and interface served separately -> can connect to different machines without switching apps.
- Remote software updates introduced
The general workflow consisted of creating technical proposals that addressed the clients needs from an automation point of view. This included suggesting new ways machines could be used to drive operational enhancements, not just remove manual, tedious labour.
Being a somewhat “modern” software engineer, working in an agile way appeals, but this can become a fuzzier process with hardware based products. Iterating on complete designs get more impractical and expensive the bigger the object. Software development encourages the offloading of common, well established tasks to third party systems but this doesn't extend as easily into hardware. At the prototype stage, in-house manufacturing can play a key role in moving quickly.
So, in reality, a mixture of agile and waterfall methods were used. Overall machine philosophy and subsystem interface standards needed to be sorted upfront but subsystems were loosely left as “plausible ideas”.
As cost estimates needed to be provided for client company budgeting, machine development was broken down into blocks of decoupled work (by subsystem) that could be used as a guide for iteration planning. Any hold-ups on one subsystem, manufacturing or otherwise would, not greatly impact the overall time frame for delivery.
This approach worked well. During the design of one machine, a cartesian CNC pickup subsystem was successfully replaced with a scara robot arm very late in the development cycle. While this did require substantial changes to the frame and enclosure, other parts of the system were unaffected. The standard vacuum subsystem was also swapped out for a compressed air vacuum generator, without requiring any changes to the core system or software.
Having grown a little tired of Jira I tried Clickup for this project. The sprint template and general list flexibility is fantastically simple and productive. Having docs tightly integrated is a real bonus too. It is however rather slow and bad at syncing, but with a small team and small project, that’s manageable (they seem to be doing a classic we need to re-write/re-architect our stack -> delays...).
Anyway, when designing the second/third machines it was super simple to create extra folders so each machine had it’s own lists and master documentation, but tasks could be easily pulled into the shared 2 week sprint cycles.
I settled on having a space structure like:
Sprint folder
- Sprint 1 list
- Sprint 2 list
- ...
Machine 1 folder
- Backlog list
- Ideas list
- Bug list
- Processes & tests list
- Docs
Machine 2 folder
- Backlog list
- ...
It’s easy to give clients access to sprint or a simplified progress list so they can see what’s going without overwhelming them. Each block of work was followed by a reporting adding context to the completed work. The reports were publish in a blog like format.


Mockups were done in Figma. This was before I started playing with TailwindUI and Flowbite components - they would have saved me a lot of time and improved the somewhat basic prototype UIs! Apart from obviously being good for UI mockups, Figma has proved most valuable for creating technical diagrams. I wish I could have Figma natively in Clickup, their whiteboarding solution is no match.
On the face of it, a simple prototype machine doesn’t require centralised/cloud capabilities. However, when placed in a non-technical environment for testing 6000 miles away, some cloud functionality comes in very handy. The main use cases in this scenario were remote updates and machine discovery (by the separately hosted UI), although there are plenty more uses past the prototype stage.
Having used serverless architecture towards the end of my previous job (and managed infrastructure before that) rolling out some AWS services with the CDK was an easy and cost effective choice to make. Below is a simplified infrastructure diagram showing
- UI being statically served through CloudFront and S3
- A GraphQL API with Cognito auth, backed by Lambdas, DynamoDB and Step Function
- An ingest pipeline going through IoT core (MQTT messaging), to Kinesis, Lambda and piped into another S3 bucket.

Originally, UI apps were served from the machines but this meant any small updates (which were much more likely on the frontend) needed a full machine update. Shifting these apps to web hosted with a local machine discovery process removed that coupling, so a browser refresh is all that’s needed by the customer to get the latest copy. Different app versions can be hosted online and deployed in parallel, so a stable version is always available. Removing the app from the machine also freed up computing resources.
When it come to implementing remote updates, a lot of the heavy lifting (security, messaging, asset hosting) can be pulled in through AWS services. An example of how that can be done:
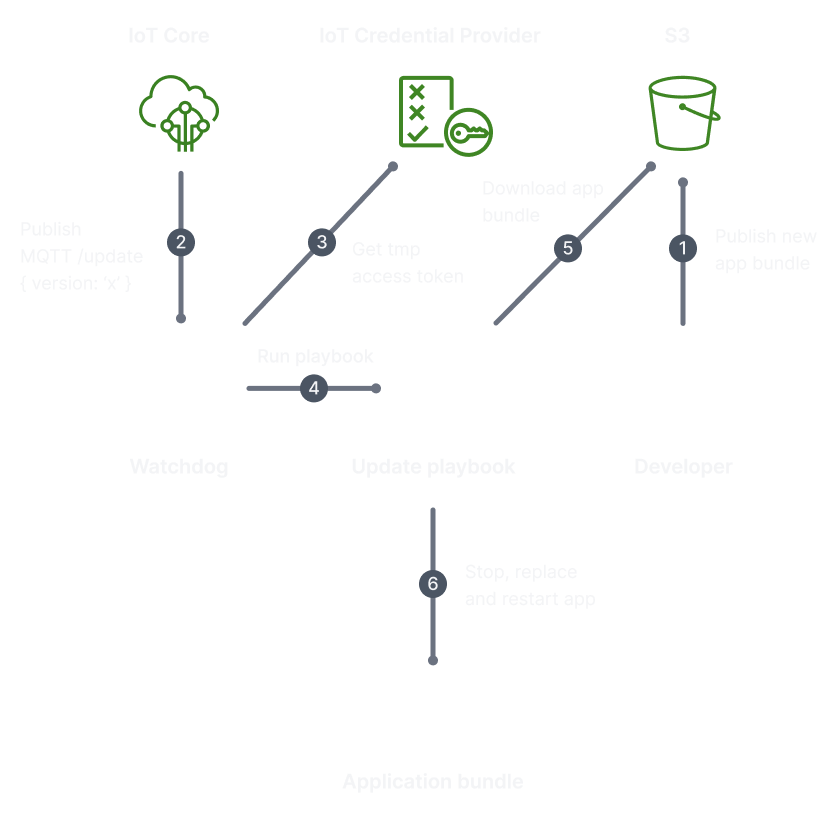
The machines have an onboard SBC that runs the main application and a watchdog, both written in TypeScript (Node.js). This is perhaps not the obvious choice, but for prototyping, the tooling and library options combined with native async I/O works well. It must be noted that the machine(s) core system has no need for true realtime capabilities. There are subsystems that require realtime processing and they naturally have a different solution.
XState and GraphQL on top of an event bus and embedded database provide the core functionality, exposing an API that the UI or other machines can communicate with. GraphQL subscriptions are used to provide neartime updates to the UI.
As the machines are running Linux, plenty of provisioning tools are available. Ansible, which I used a lot at my previous job, works nicely as an idempotent provisioning tool (i.e. no tunnelling here) and is used to provide app and OS level updates. Again, this might seem overkill, but using a proven tool for both repeatable setup and updates ends up being easier than hacking together a simple script. The time recovered setting up a second machine more than makes up for the extra effort.
There is an app per machine type. These are statically hosted client side apps, build using React and Apollo Client. They are not particularly logic heavy and so Apollo client does a good enough job maintaining state.